- Published on
Kubernetes 개념 정리
쿠버네티스(Kubernetes)는 컨테이너화 된 애플리케이션의 대규모 배포, 스케일링 및 관리를 간편하게 만들어주는 오픈 소스 기반 컨테이너 오케스트레이션(Container Orchestration) 도구다.
쿠버네티스에 10개의 물리적 서버가 있다면 내가 만든 App은 1번 서버, 다른 개발자의 App은 2번 서버 이렇게 각각 올라가는 것이 아니라 서로 다른 App 모두 같은 물리적 서버를 공유할 수 있어서 한꺼번에 올라가며, 쿠버네티스에 의해 분배, 관리(Container Orchestration) 되는 구조이다.
목차
- Kubernetes Cluster
- Kubernetes Object
Kubernetes Cluster
쿠버네티스를 이루는 구성은 다음과 같다.
Cluster > Node(WorkerMachine) > Pod(하나이상의 컨테이너화된 Application으로 구성)
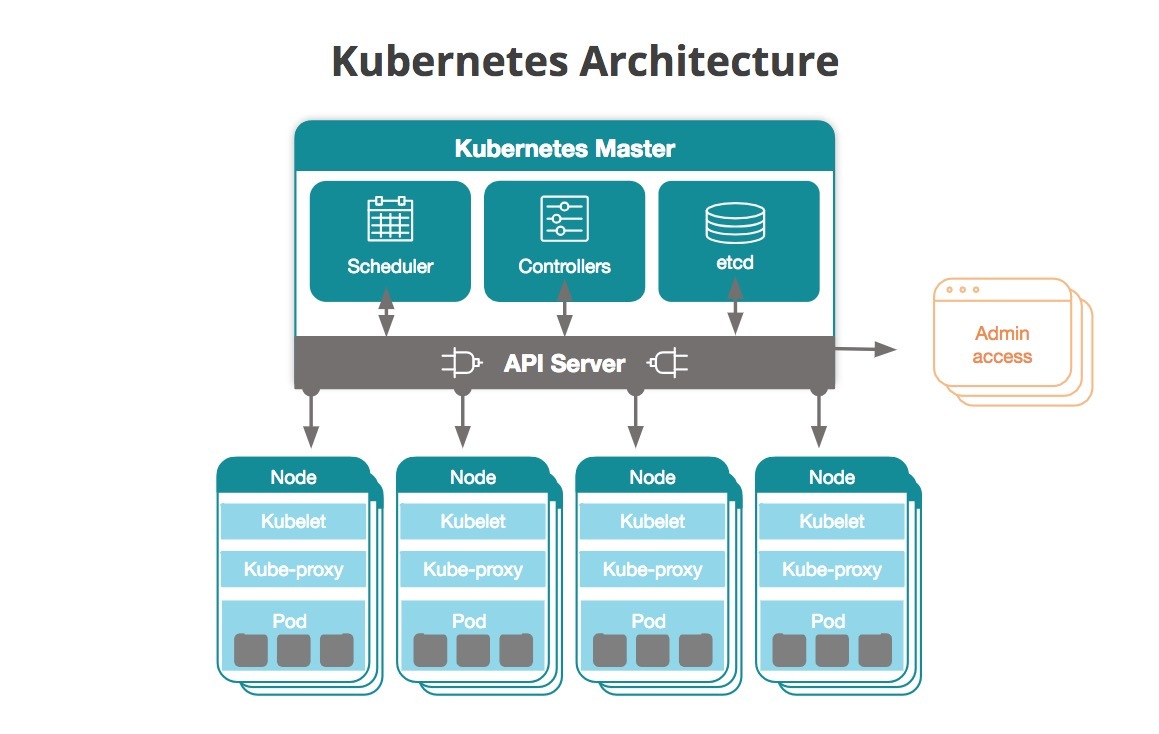
쿠버네티스의 Cluster는 Master노드와 Worker노드로 이루어져 있다.
Master 노드
워커노드를 모니터링 & 스케쥴링하고 서비스와 pod등을 적재, 관리한다.
마스터노드는 아래와 같은 컴포넌트들을 가지고 있다.
- Kube-Scheduler : Pod, 서비스 등을 적절한 워커노드에 할당
- kube-controller-manager : Kubernetes Cluster의 모든 Pod들을 관리하는 컨트롤러를 실행하는 역할을 한다.
- Node Controller : Node가 다운되었을 때 통지와 대응을 한다.
- Replication Controller : 적절한 수의 Pod를 유지해주는 역할을 한다
- End-Point Controller : Service와 Pod를 연결해주는 역할을 한다.
- Service Account / Token Controller : 새로운 namespace에 대한 기본 계정과 API 접근 Token을 생성한다.
- Kube-ApiServer : Kubernetes는 모든 명령과 통신을 API를 이용하며 Kubernetes Cluster의 API를 사용할 수 있도록 하는 서버이다. Cluster로 온 요청을 검증하고 컴포넌트끼리 통신을 주고받을수 있게하는 역할을 한다. kubectl도 내부적으로 api를 호출한다.
- ETCD : key-value 저장소(redis같은). 쿠버네티스에서 ETCD에 여러가지 메타데이터를 저장하는데 중요한 것들은 아래와 같다.
- Node, Pod, 설정, 암호, 계정, 역할
Worker 노드
마스터노드에서 스케쥴링 해주는 오브젝트를 적재하며, Pod들을 유지 및 런타임 환경을 제공한다. 워커노드는 아래와 같은 컴포넌트들을 가지고 있다.
-
kubelet : k8s Cluster의 모든 Node에서 실행되며 Pod의 spec을 전달받아 Container들이 실행되는것을 관리 및 실행여부를 체크하는 역할을한다. (api서버의 명령을 listen하여 pod의 상태검사, 생성, 삭제 작업을 한다.) Master의 API서버와 통신하며 Node가 수행해야할 명령을 받거나 노드의 상태를 Master한테 전달해준다.
-
kube-proxy : kubernetes Cluster안에서 가상 네트워크를 동작할 수있게하는 역할을 한다. Node로 들어오는 네트워크 트래픽을 적합한 container로 라우팅하며 Node의 네트워크 트래픽을 로드밸런싱해준다. 클러스터내의 Pod와 서비스의 연결을 통해 pod끼리의 통신을 가능하게 한다.
Kubernetes Object
쿠버네티스 Object는 쿠버네티스 시스템에서 영속성을 가지는 오브젝트이다. 즉 오브젝트가 생성되면 쿠버네티스는 이 상태를 영구히 유지하기 위해 작동한다.
쿠버네티스의 오브젝트는 spec과 status등의 값을 가지는데, 여기에는 오브젝트를 생성한 의도나 오브젝트를 관리할 때 원하는 상태 등을 설정한다.
쿠버네티스에는 다음과 같은 기본 Object들이 있는데, 이에 대해 알아본다.
Pod
Pod는 쿠버네티스 에서 이용되는 Container의 관리단위로 생성/관리/배포가능한 가장작은 단위의 유닛이며 Cluster내에서 실제 Application이 구동되는 Object다.
Pod는 하나 이상의 Container로 구성되며, 동일한 Pod 내에서는 storage/network를 공유 할 수 있다.
몇 가지 Pod 설정에 대해 알아본다.
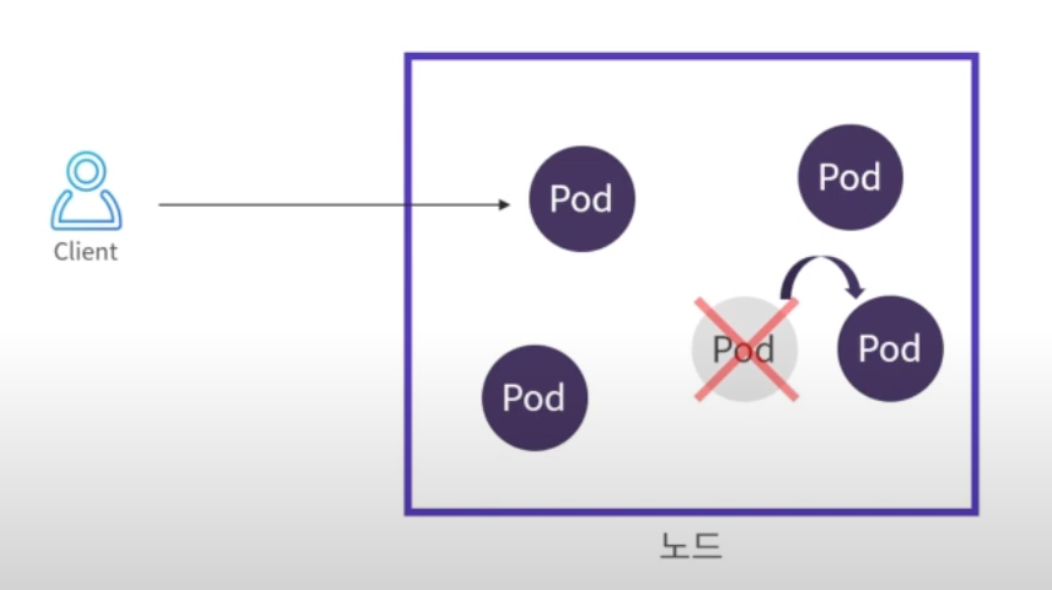
Pod에 리소스 제한 (cpu, memory) 설정을 해야 하는 이유
Pod 하나가 너무 많은 리소스를 사용하게 되면 노드안의 다른 Pod들도 먹통이 될 수 있다.
리소스 제한을 설정하면 아래 그림 처럼 Pod가 리소스제한까지 사용했을 때 쿠버네티스에서 해당 Pod만 재시작해준다.
참고로 https://techblog.lycorp.co.jp/ko/efficiently-using-cpu-in-kubernetes 에서 cpu request, limits 설정에 대한 테스트 결과를 공유하고 있다.
또한 CPU limits on Kubernetes are an antipattern 을 참고하여, cpu limit 설정은 제거하고, memory limit 설정은 request 와 동일하게 설정하라는 내용도 참고해보면 좋다.
cpu, memory 리소스 제한 설정은 아래의 resources 부분을 참고한다.
spec:
containers:
- name: hubot-hey-cookie
image: hubot-hey-cookie
imagePullPolicy: IfNotPresent
env:
- name: HUBOT_SLACK_TOKEN
valueFrom:
secretKeyRef:
name: hubot-slack-token
key: HUBOT_SLACK_TOKEN
resources:
limits:
cpu: 2
memory: 2Gi
requests:
cpu: 1
memory: 1Gi
restartPolicy: Always
특정 Worker 노드에만 Pod 배포하기
특정 Pod가 Heavy한 작업을 하여 같은 노드내의 다른 Pod에도 영향을 줄 수 있다면 배포되는 Worker노드를 따로 분리하는게 좋다.
nodeAffinity를 통해 특정 Worker 노드에만 Pod를 배포할 수 있다.
아래에서 Pod를 key는 disktype이고 value는 ssd인 노드에만 배포해달라고 설정할 수 있다.
이를 통해 Heavy한 Batch작업 Pod와 서비스를 해야하는 Pod를 나누어서 다른 노드에 배포할 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
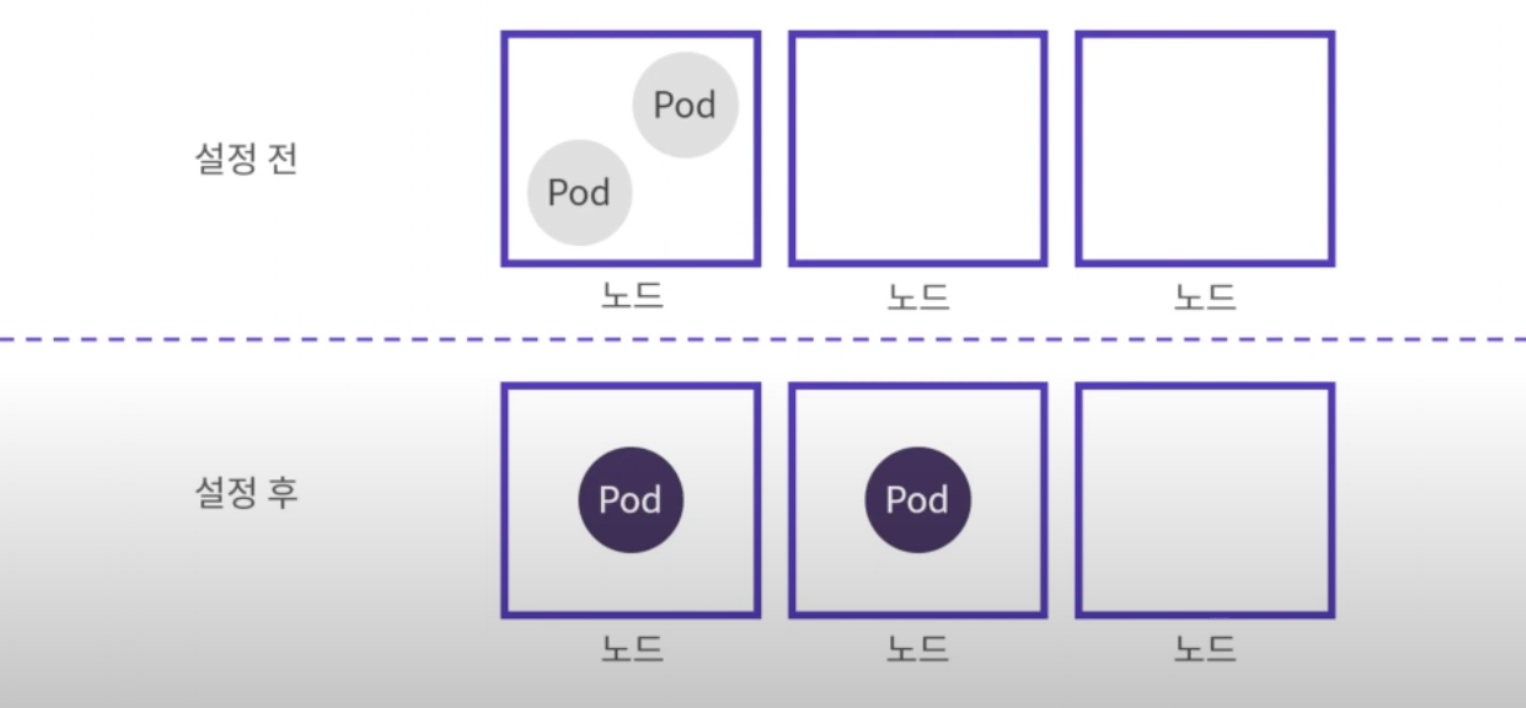
여러 노드에 분산해서 Pod 배포하기
podAntiAffinity를 통해 같은 노드가 아닌 여러 노드에 분산해서 Pod를 배포할 수 있다.
아래에서 podAntiAffinity 설정을 통해 "key는 app이고 value는 store인 Pod를 피해서 배치해줘" 라고 요청할 수 있다. 그러면 label이 app: store 인 Pod들은 같은 노드에 배치되지 않고 모두 다른 노드에 분산되어 배치된다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-cache
spec:
selector:
matchLabels:
app: store
replicas: 3
template:
metadata:
labels:
app: store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: 'kubernetes.io/hostname'
containers:
- name: redis-server
image: redis:3.2-alpine
다음 그림과 같이 배치된다.
추가로 affinity 외에 토폴로지 분산 제약을 이용한 Pod 분산 처리 방법도 있다. 아래 링크를 참고한다.
쿠버네티스에서 파드를 분산 처리하기 위한 토폴로지 분배 제약 조건 활용 사례 소개
Liveness, Readiness Prove
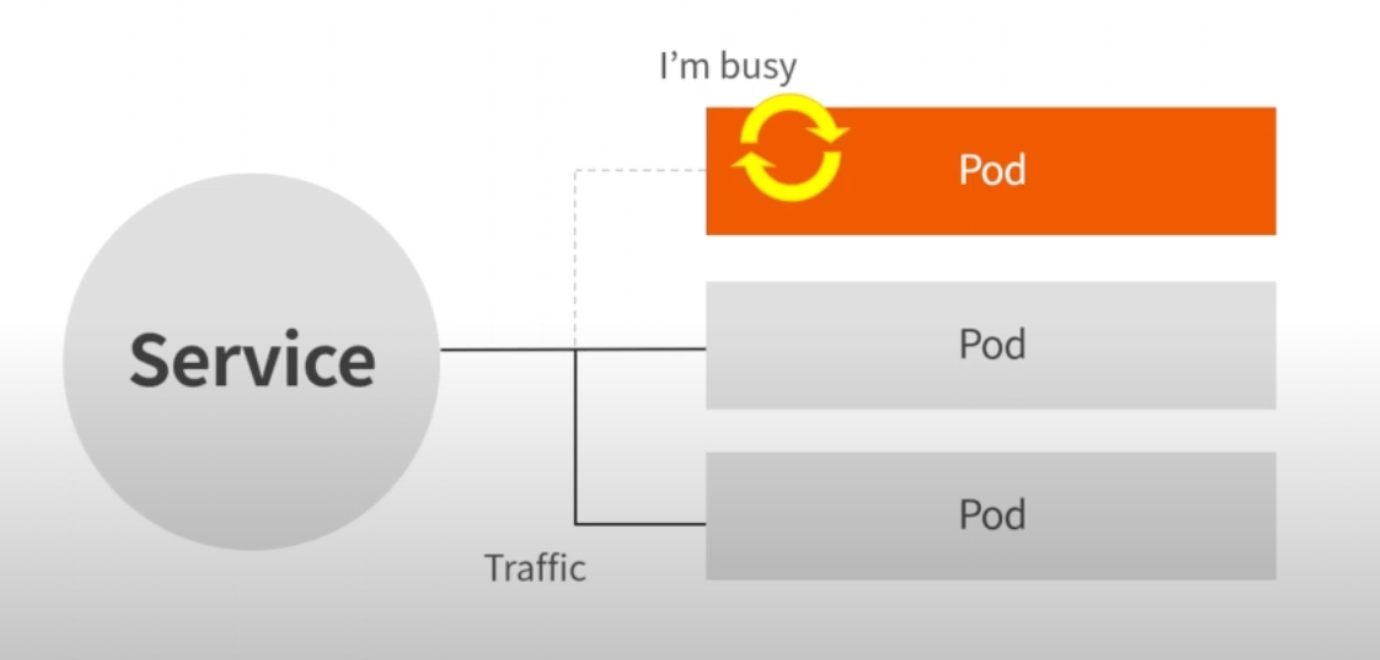
Liveness Prove는 Pod는 살아있는데 App서비스가 비정상인 경우 Liveness Prove를 통해 Health Check를 하여 응답이 없으면 자동으로 재시작해준다.
Readiness Prove는 Pod가 배포중이거나 하여 준비상태가 아닌 경우 Service에서 해당 Pod로는 트래픽을 보내지 않게 설정하는 방법 (Liveness Prove 처럼 설정한 path, port로 Health Check를 하여 체크한다.)
[Readiness Prove 설정시]
Horizontal Pod Autoscaling
K8S Control Plane 내에서 실행되는 HPA 컨트롤러는 평균 CPU 사용률, 평균 메모리 사용률등의 관측된 메트릭을 목표에 맞추기 위해 Deployment 의 Pod 수를 주기적으로 조정한다.
https://kubernetes.io/ko/docs/tasks/run-application/horizontal-pod-autoscale/
hpa:
minReplicas: 4
maxReplicas: 8
cpuAverage: 70
memoryAverage: 80
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: {{ .Values.application.name }}-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: {{ .Values.application.name }}-deployment
minReplicas: {{ .Values.hpa.minReplicas }}
maxReplicas: {{ .Values.hpa.maxReplicas }}
metrics:
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: {{ .Values.hpa.memoryAverage }}
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: {{ .Values.hpa.cpuAverage }}
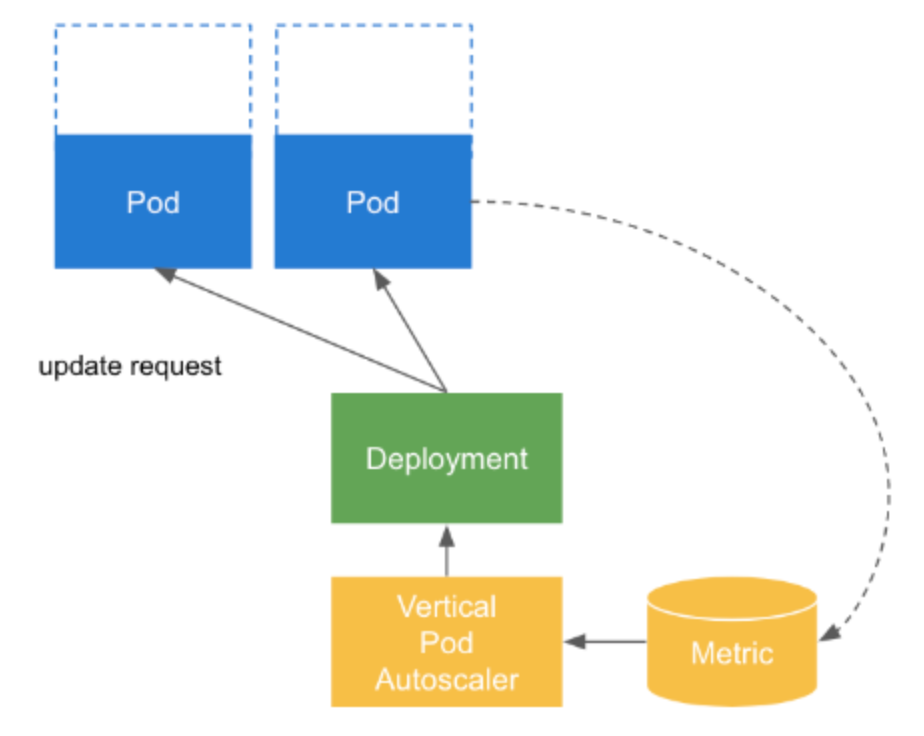
Vertical Pod Autoscaling
https://github.com/kubernetes/autoscaler
- Kubernetes 클러스터에서 실행되는 Pod에 필요한 리소스 요청을 계산해줍니다.
- 권장사항에 따라 pod의 CPU 및 메모리 양을 자동으로 조정해줍니다.
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: my-app-vpa
spec:
targetRef:
apiVersion: 'apps/v1'
kind: Deployment
name: my-app
updatePolicy:
updateMode: 'Auto'
-
updateMode의 종류
- Auto
- pod 생성 시점에 리소스를 할당하고, 이후에는 리소스를 자동으로 갱신하는 모드
- 하지만 현재는 Recreate 모드와 다를바가 없습니다. 이후에 pod 를 재시작하지 않고도 리소스를 갱신할 수 있는 in-place 업데이트가 가능해지면 효율적인 리소스 관리가 가능
- Recreate
- pod 생성 시점에 리소스를 할당하고, 이후 기존 파드의 리소스 요청이 크게 변경되면 pod를 재시작합니다.
- Initial
- pod가 생성될 때만 리소스 요청을 할당하며 이후에는 리소스를 변경하지 않습니다.
- 즉 초기 리소스를 설정할때만 VPA의 도움을 받습니다.
- Off
- VPA가 pod의 리소스를 자동으로 변경하지 않는 모드입니다.
- VPA의 권장 사항을 참고하여 수동으로 리소스를 조정하고자 할때 사용합니다.
- Auto
-
주의 사항
- VPA는 파드가 재시작될 때만 리소스를 조정하므로, VPA가 활성화된 상태에는 파드가 재시작될 수 있음을 염두에 두어야 합니다.
- VPA와 HPA를 동시에 사용하는 경우 두 오토스케일러가 충돌하지 않도록 주의해야합니다.
-
결론
- VPA는 현재로서는 pod의 리소스를 높이려면 pod를 재시동해야하는 한계가 있습니다. 또한 HPA와 동시에 사용하는 경우 충돌의 위험이 있으니 필요에 따라 하나만 선택해서 사용하는 것을 권장합니다.
- HPA의 min/max replica 세팅의 경우 특별히 권장하는 사항은 없습니다. 단, 하나의 클러스터에 여러 네임스페이스를 운영하는 경우 노드 리소스를 여러 서비스가 공유하기 때문에 min / max 값의 차이를 두고 리소스 여유분을 남기고 운영하는 것을 추천합니다.
Deployment
- Pod의 scale in / out 되는 기준을 정의한다.
- Pod의 배포되고 update 되는 모든 버전을 추적할 수 있다.
- 배포된 Pod에 대한 rollback을 수행할 수 있다.
즉, 개념적으로 Deployment = ReplicaSet + Pod + history이며 ReplicaSet 을 만드는 것보다 더 윗 단계의 선언(추상표현)이다.
롤링 업데이트 전략
롤링 업데이트는 old 버전의 Pod를 하나씩 제거하는 동시에 new 버전 Pod를 추가하는 배포전략이다.
업데이트 중 old 버전과 new 버전이 동시에 서비스되기 때문에, App이 반드시 old버전, new버전 간에 하위호환성이 보장되어야 한다.
- maxSurge
- 기본값 25%, 개수로도 설정가능
- 최대로 추가 배포를 허용할 개수 설정
- 4개인 경우 25%이면 1개가 설정. (new version 1개 + old version 4개 = 총 5개까지 동시 포트 운영됨)
- maxUnavailable
- 기본값 25%, 개수로도 설정가능
- 동작하지 않는 포드의 개수 설정
- 4개인 경우 25%이면 1개가 설정. (롤링 업데이트 중 최소 4 - 1 = 3개의 포드는 운영되고 있도록 보장)
spec:
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
Namespace
쿠버네티스에서는 pod, deployment, statefulset, secret 등의 오브젝트들을 클러스터내에서 논리적으로 분리할 수 있는 namespace를 제공하고 있다. 오브젝트들을 묶은 하나의 가상 공간 또는 그룹이라고 이해할 수 있다.
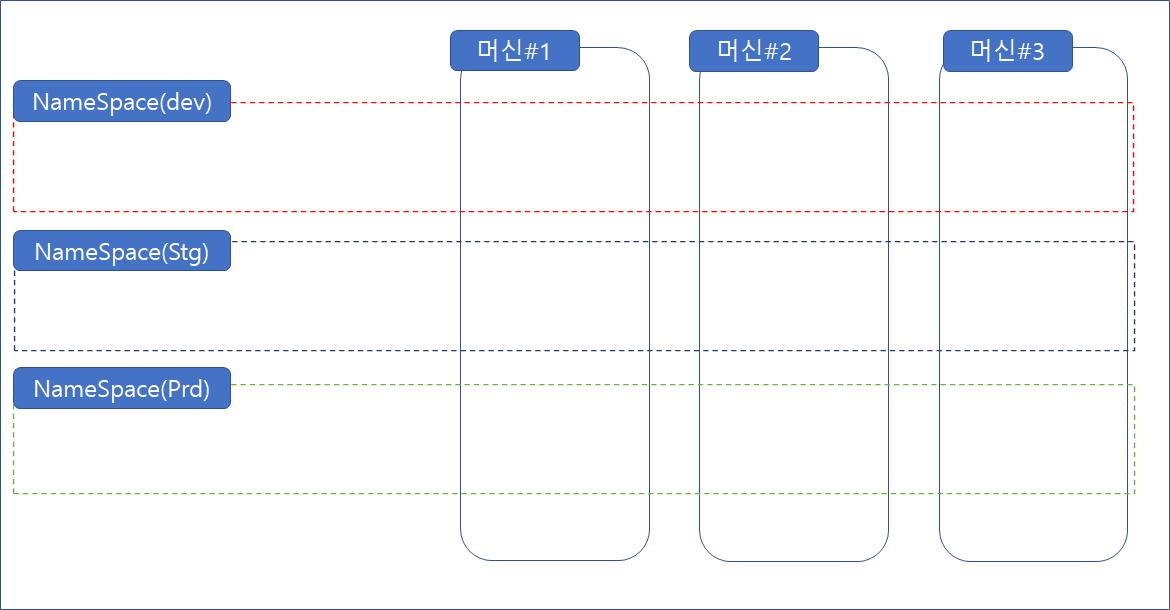
위 그림에서 dev/stg/prd 세 개의 namespace로 구분하였다.
dev 목적의 사용자는 dev namespace에 접근하여 오브젝트를 배치 또는 운영하고, stage 목적의 사용자는 stg namespace에 접근하여 운영한다.
중요한 것은 namespace는 클러스터를 논리적으로 분리하는 것이지, 물리적으로 분리하는 것은 아니다! 라는 것이다.
(클러스터의 장애가 발생할 경우, 모든 namespace가 타격을 입게 된다. isolation을 원할 경우, 쿠버네티스 클러스터를 다중화/이중화 함으로써 해결해야 한다.)
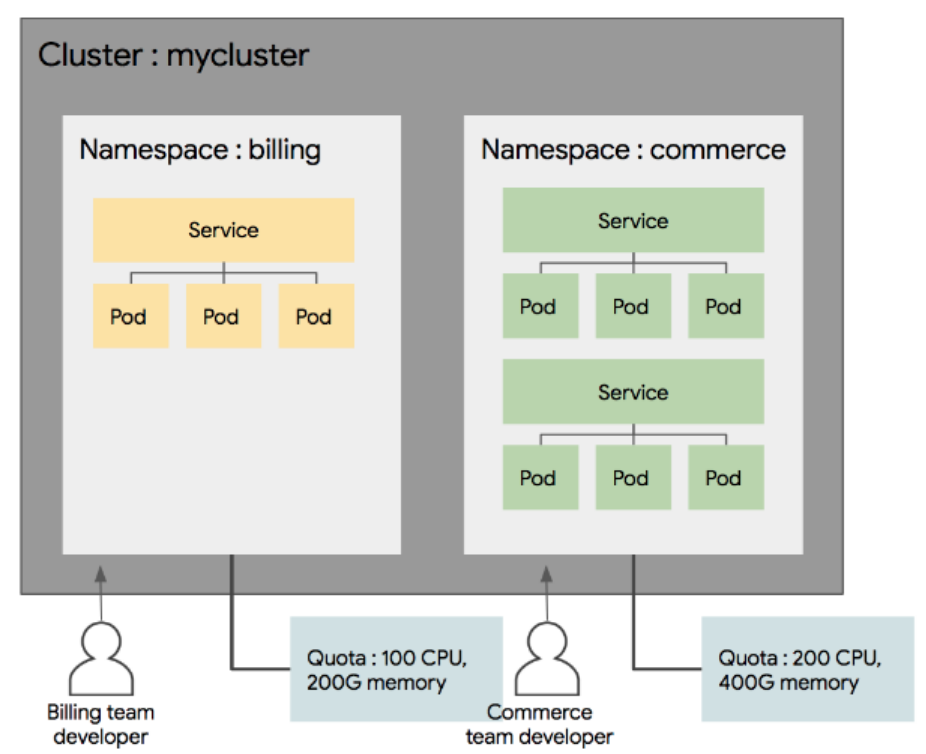
위 그림에서 보듯이 namespace별로 리소스 할당량을 지정할 수 있다. 또한 사용자별로 namespace 접근 권한을 관리할 수 있다.
네임스페이스 를 왜 구성하는가
-
자원격리 : 네임스페이스를 사용하면 서로 다른 팀이나 프로젝트가 동일한 클러스터를 공유하면서도 자원을 격리하여 사용할 수 있습니다. 이는 서로 다른 팀의 애플리케이션이 서로 간섭하지 않도록 합니다.
-
각 네임스페이스에 대해 설정된 리소스 쿼터는 해당 네임스페이스가 사용할 수 있는 최대 CPU와 메모리 양을 제한합니다.
-
각 네임스페이스에 배포된 애플리케이션은 설정된 리소스 쿼터 내에서만 실행되며, 다른 네임스페이스의 리소스와 격리됩니다.
namespace project-a
apiVersion: v1 kind: ResourceQuota metadata: name: quota-project-a namespace: project-a spec: hard: requests.cpu: '2' requests.memory: '2Gi' limits.cpu: '4' limits.memory: '4Gi' --- apiVersion: apps/v1 kind: Deployment metadata: name: nginx-a namespace: project-a spec: replicas: 2 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:latest resources: requests: memory: '512Mi' cpu: '500m' limits: memory: '1Gi' cpu: '1'namespace project-b
apiVersion: v1 kind: ResourceQuota metadata: name: quota-project-b namespace: project-b spec: hard: requests.cpu: '1' requests.memory: '1Gi' limits.cpu: '2' limits.memory: '2Gi' --- apiVersion: apps/v1 kind: Deployment metadata: name: nginx-b namespace: project-b spec: replicas: 1 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:latest resources: requests: memory: '256Mi' cpu: '250m' limits: memory: '512Mi' cpu: '500m'
-
-
이름 충돌 방지 : 네임스페이스는 동일한 이름의 리소스(예: Pod, Service 등)가 클러스터 내에서 존재할 수 있도록 합니다. 각 네임스페이스 내에서 이름이 고유하면 됩니다
-
액세스 제어: RBAC(Role-Based Access Control)와 결합하여 네임스페이스 단위로 접근 권한을 설정할 수 있습니다. 이를 통해 특정 사용자나 그룹이 특정 네임스페이스에만 접근하도록 제한할 수 있습니다.
-
RBAC (Role-Base Access Control)
-
ServiceAccount, Role, ClusterRole 등의 resource 를 활용 하여 Cluster Resource 에 대한 접근 권한을 정의. 정의 하지 않을 시 모든 권한 열려 있음
-
Role : namespace 내에 부여 되는 권한 set
- 'pod-reader' 라는 Role을 생성하여 'get', 'list' 권한을 'pods' 리소스에 부여
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: namespace: my-namespace name: pod-reader rules: - apiGroups: [''] resources: ['pods'] verbs: ['get', 'list'] -
RoleBinding : Role / ClusterRole 을 특정 namespace 에 binding 할 때 사용. 역할이 특정 네임스페이스에 한정된 정책을 따르도록 적용
- 'read-pods' 라는 RoleBinding 을 생성하여 'my-service-account' 에 'pod-reader' Role 을 바인딩
- 'my-service-account' 는 'my-namespace' 내의 Pod에 대해 조회 및 나열 권한을 가지게 됨
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: read-pods namespace: my-namespace subjects: - kind: ServiceAccount name: my-service-account namespace: my-namespace roleRef: kind: Role name: pod-reader apiGroup: rbac.authorization.k8s.io
-
ClusterRole : namespace 를 넘어 cluster 범위에 유효한 권한 set. role 은 지역변수 개념이라면 clusterRole 은 전역변수 개념
-
ClusterRoleBinding : ClusterRole 을 Cluster 의 모든 namespace 에 binding 할 때 사용. Role이 클러스터 전체에 한정된 정책을 따르도록 적용할 때
-
-
-
리소스 할당(Resource Quota) : 네임스페이스별로 리소스 쿼터를 설정할 수 있습니다. 이를 통해 각 네임스페이스가 사용할 수 있는 CPU, 메모리 등의 리소스를 제한하여 클러스터 전체 자원을 효율적으로 관리할 수 있습니다.
- https://kubernetes.io/ko/docs/concepts/policy/resource-quotas/
- 리소스 쿼터는 네임스페이스 내의 모든 Pod와 컨테이너에 걸쳐 적용되며, 설정된 한도를 초과하면 새로운 리소스를 생성할 수 없습니다. 이를 통해 클러스터 자원의 과도한 사용을 방지하고, 여러 팀이나 프로젝트가 동일한 클러스터를 사용할 때 자원을 공정하게 분배할 수 있습니다.
- 예시
- requests.cpu와 requests.memory: 네임스페이스 내에서 요청할 수 있는 총 CPU와 메모리 양을 제한합니다. 이는 Pod가 시작될 때 요청하는 최소 리소스 양을 의미합니다.
- limits.cpu와 limits.memory: 네임스페이스 내에서 사용할 수 있는 최대 CPU와 메모리 양을 제한합니다. 이는 Pod가 사용할 수 있는 최대 리소스 양을 의미합니다.
apiVersion: v1 kind: ResourceQuota metadata: name: my-quota namespace: my-namespace spec: hard: requests.cpu: '1' # 네임스페이스 내의 총 CPU 요청을 1 코어로 제한 requests.memory: '1Gi' # 네임스페이스 내의 총 메모리 요청을 1Gi로 제한 limits.cpu: '2' # 네임스페이스 내의 총 CPU 사용을 2 코어로 제한 limits.memory: '2Gi' # 네임스페이스 내의 총 메모리 사용을 2Gi로 제한
-
환경 분리: 개발, 테스트, 프로덕션과 같은 다양한 환경을 네임스페이스로 구분하여 관리할 수 있습니다. 이를 통해 환경별로 설정을 분리하고, 배포를 독립적으로 관리할 수 있습니다.
어떻게 Namespace를 구성하면 좋을까?
-
각 프로젝트가 환경별로 클러스터/네임스페이스 구성
[Dev Cluster] ← (A Project 전용) ├── Namespace: dev ├── Namespace: alpha └── Namespace: beta [Prod Cluster] ← (A Project 전용) ├── Namespace: prod └── Namespace: hotfix- 장점 : 비교적 구성이 단순해지며, 프로젝트 간의 리소스 영향도가 적다.
- 단점 : 각 프로젝트별로 클러스터를 관리하게 되므로 관리해야하는 클러스터의 수가 늘어나게 된다. 자원의 소모가 많을 수 있다.
-
여러 프로젝트가 개발용, 제품용 2개의 클러스터에 환경별로 네임스페이스 로 구성
[Shared Dev Cluster] ├── Namespace: projectA-alpha ├── Namespace: projectB-beta └── Namespace: projectC-alpha [Shared Prod Cluster] ├── Namespace: projectA-prod ├── Namespace: projectB-prod └── Namespace: projectC-prod- 장점 : 신규 프로젝트가 기존 클러스터에 네임스페이스만으로 배포되므로 확장성이 용이하다. 여유분 리소스를 확보하여 확보한 리소스를 여러 프로젝트에서 적절하게 공유하여 사용이 가능하다.
- 단점 : 프로젝트 별 리소스 관리가 어렵다. 예상치 못한 리소스 증가에 대응하기 어려울 수 있다. nodepool 을 이용하여 프로젝트 별로 node 관리 구성을 할 필요가 있을 수 있다.
Volume
Volume은 Pod가 사라지더라고 저장/보존이 가능하며 Pod에서 사용할 수 있는 디렉터리를 제공한다.
쿠버네티스에서 Pod는 고정된 개념이 아니며 끊임없이 사라지고 생성된다. 그렇기 때문에 Pod는 디렉터리도 임시로 사용한다. Pod가 사라지더라도 사용할 수 있는 디렉터리는 볼륨 오브젝트를 통해 생성하여 사용할 수 있다.
Service
Service는 Pod 앞단에서 네트워크 말단이 되는 리소스이다.
Label Selector를 통해서 Pod를 타겟팅하고 로드밸런싱 역할을 한다.
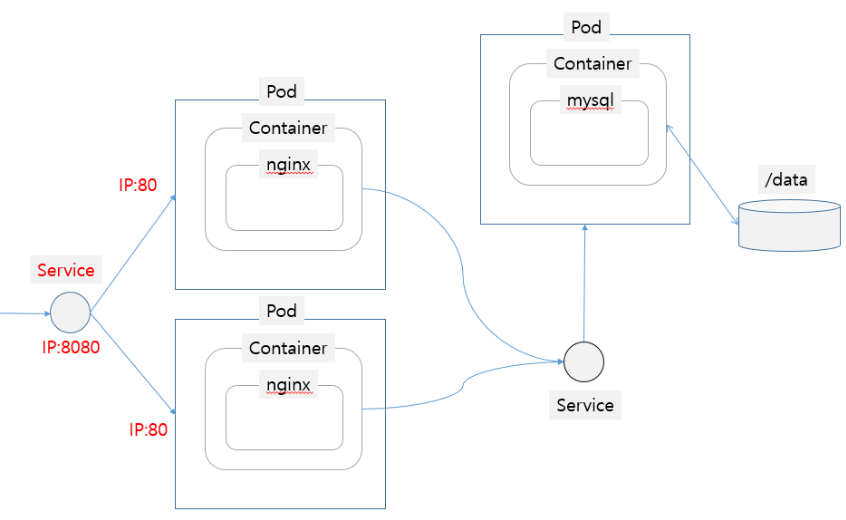
Service에는 다음과 같은 타입이 있다.
- Cluster IP : 쿠버네티스의 디폴트 설정으로 외부에서 접근가능한 IP를 할당받지 않기 때문에 Cluster내에서만 해당 서비스를 노출할 때 사용되는 Type
- NodePort : 해당 서비스를 외부로 노출시키고자 할 때 사용되는 Service Type으로 외부에 Node IP와 Port를 노출시킴
- LoadBalancer : 클라우드상에 존재하는 LoadBalancer에 연결하고자 할 때 사용되는 Service Type으로 LoadBalancer의 외부 External IP를 통해 접근이 가능하다.
그리고 Service yaml 파일에 기술된 name으로 쿠버네티스 클러스터상에 DNS를 생성할 수 있다.
쿠버네티스는 자체 DNS서버를 가지고 있어 클러스터 내부에서만 사용가능한 DNS를 설정해서 사용할 수 있다.
이것은 쿠버네티스상에서 통신할때 IP기반이 아닌 DNS를 통해 연결할 수 있음을 뜻하며 위의 그림과 같이 Pod에서 다른 Pod의 서비스를 연결할때 사용된다.
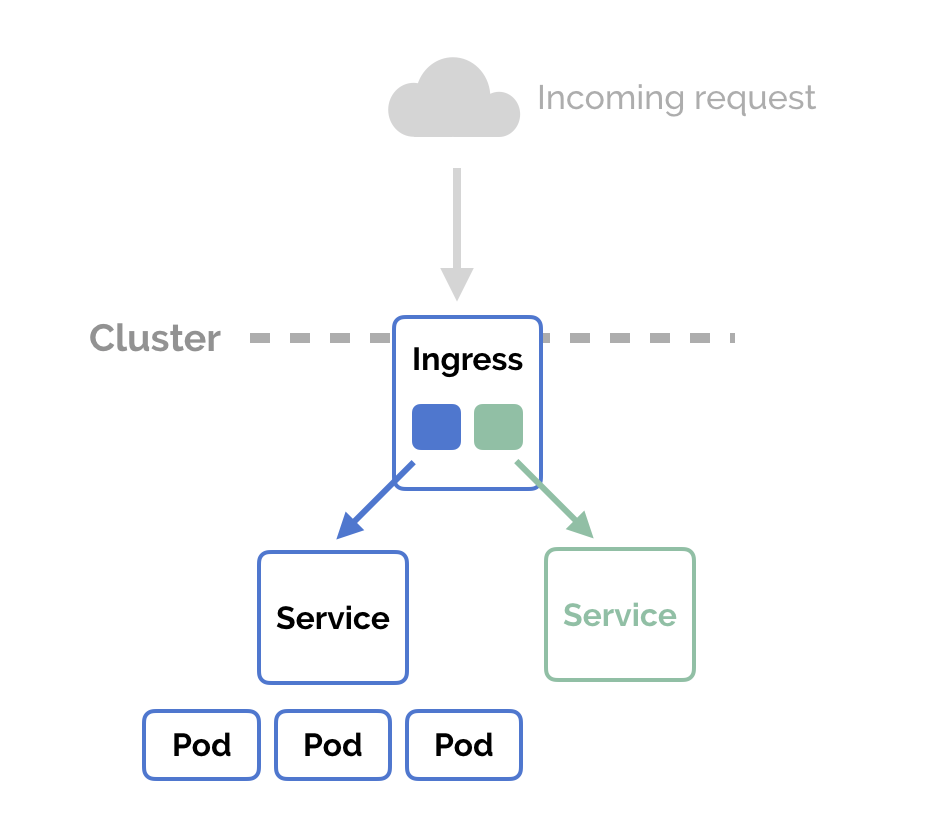
Ingress
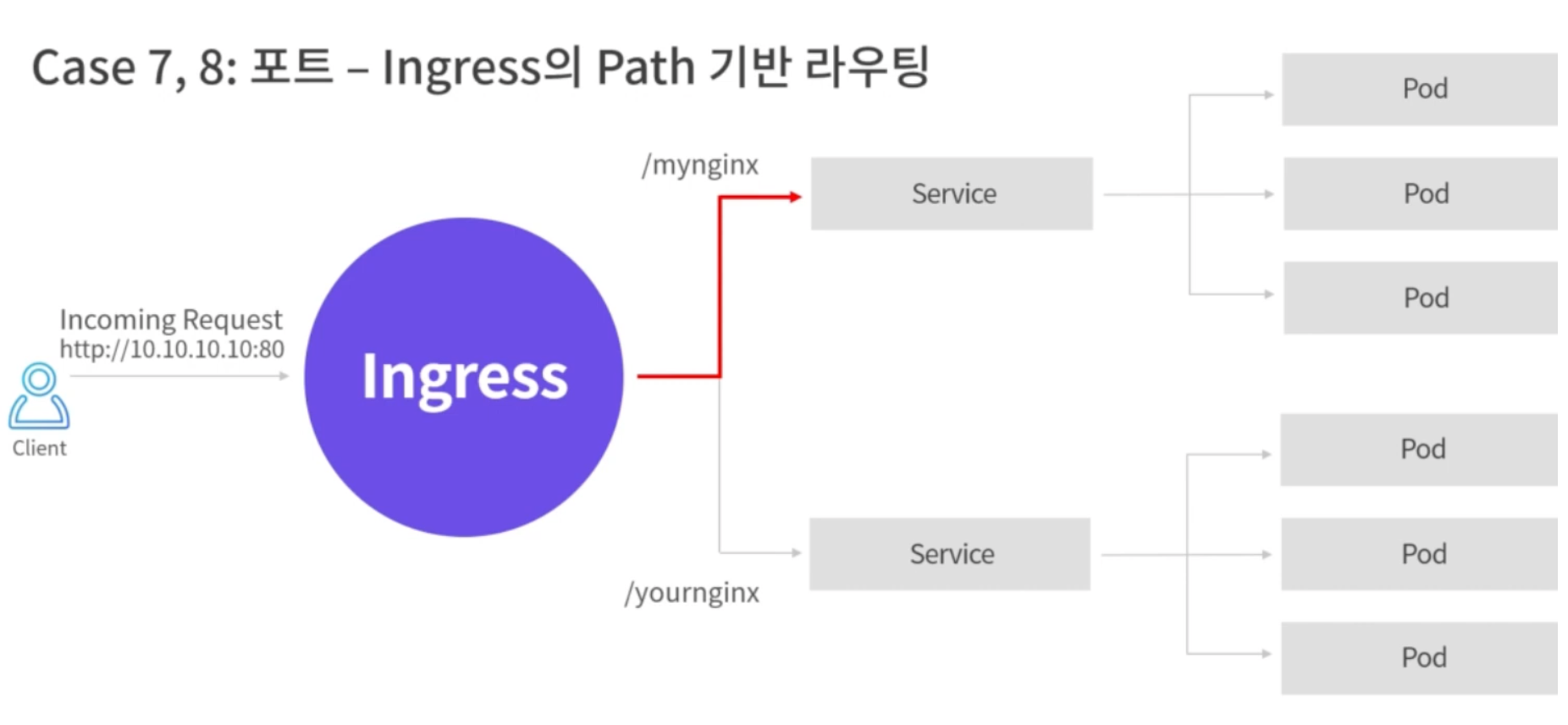
Ingress는 외부에서 들어온 HTTP와 HTTPS 트래픽을 ingress resouce를 생성하여 Cluster내부의 Service로 L7영역에서 라우팅하며 로드밸런싱, TLS, 도메인 기반의 Virtual Hosting을 제공한다.
아래와 같이 Ingress를 통해 Path기반으로 라우팅을 설정할 수 있다.
다음의 Service & Ingress를 설정한 yaml 파일을 참고한다.
apiVersion: v1
kind: Secret
metadata:
name: fintech-prod
type: Opaque
---
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: fintech-prod
app.kubernetes.io/part-of: fintech-prod
name: fintech-prod
spec:
ports:
- name: fintech-prod
port: 3000
protocol: TCP
targetPort: 3000
selector:
app.kubernetes.io/name: fintech-prod
app.kubernetes.io/part-of: fintech-prod
type: ClusterIP
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: fintech-prod
app.kubernetes.io/part-of: fintech-prod
name: fintech-prod
spec:
replicas: 3
revisionHistoryLimit: 2
selector:
matchLabels:
app.kubernetes.io/name: fintech-prod
strategy:
rollingUpdate:
maxUnavailable: 15%
type: RollingUpdate
template:
metadata:
labels:
app.kubernetes.io/name: fintech-prod
app.kubernetes.io/part-of: fintech-prod
spec:
automountServiceAccountToken: false
containers:
- command:
- sh
- -c
- yarn start
envFrom:
- configMapRef:
name: fintech-prod
- secretRef:
name: fintech-prod
image: harbor.xxx.com/fintech/web/default
imagePullPolicy: Always
livenessProbe:
httpGet:
path: /health
port: 3000
initialDelaySeconds: 100
name: default
ports:
- containerPort: 3000
readinessProbe:
httpGet:
path: /health
port: 3000
initialDelaySeconds: 100
resources:
limits:
cpu: '1'
memory: 2Gi
requests:
cpu: 100m
memory: 128Mi
volumeMounts:
- mountPath: /var/secret
name: secret
readOnly: true
volumes:
- name: secret
secret:
secretName: fintech-prod
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
labels:
app.kubernetes.io/name: fintech-prod
app.kubernetes.io/part-of: fintech-prod
name: fintech-prod
annotations:
ingress.kubernetes.io/force-ssl-redirect: 'true'
spec:
ingressClassName: contour-private
rules:
- host: mydomain.xxx.com
http:
paths:
- backend:
service:
name: fintech-prod
port:
number: 3000
path: /
pathType: Prefix
tls:
- hosts:
- mydomain.xxx.com
secretName: tls-xxx.com
egress
egress는 ingress와 반대로 내부 네트워크에서 외부로 나가는 트래픽을 제어할 수 있다.
egress의 주요 목적은 보안 및 제어를 강화하는 것이며, 다음과 같은 중요한 기능을 가지고 있다.
- 보안 강화: 내부 네트워크에서 외부로 향하는 트래픽을 필터링하여 악성 콘텐츠, 악의적인 사이트 또는 악성 소프트웨어로부터 내부 시스템을 보호합니다. 이를 통해 내부 네트워크의 보안 취약성을 줄일 수 있습니다.
- 콘텐츠 필터링: 내부 사용자들이 특정 콘텐츠에 액세스하는 것을 제한하거나 특정 콘텐츠 카테고리를 차단함으로써 조직 정책을 시행할 수 있습니다. 이는 인터넷 사용 정책 준수를 촉진하고 내부 사용자들의 보안 및 생산성을 향상시킵니다.
- 익명성: Egress proxy를 통해 외부 서버와의 통신을 중개할 수 있으므로 내부 클라이언트의 실제 IP 주소를 숨길 수 있습니다. 이를 통해 내부 네트워크의 보안을 더욱 강화하고 외부 공격자로부터의 탐지 및 추적을 어렵게 만듭니다.
Controlling outbound traffic from Kubernetes 에서는 Egress gateways 를 설정한 과정에 대한 내용을 담고 있다.
Network Policy
NetworkPolicy 를 통해 Pod로 부터 들어오거나 나가는 트래픽을 통제할 수 있다.
일종의 Pod용 방화벽정도의 개념으로 이해하면 된다. 특정 IP나 포트로 부터만 트래픽이 들어오게 하거나 반대로, 특정 IP나 포트로만 트래픽을 내보내게할 수 있는 등의 설정이 가능하다.
Ingress 트래픽 컨트롤 정의
어디서 들어오는 트래픽을 허용할것인지를 정의하는 방법은 여러가지가 있다.
- ipBlock
- CIDR IP 대역으로, 특정 IP 대역에서만 트래픽이 들어오도록 지정할 수 있다.
- podSelector
- label을 이용하여, 특정 label을 가지고 있는 Pod들에서 들어오는 트래픽만 받을 수 있다. 예를 들어 DB Pod의 경우에는 apiserver 로 부터 들어오는 트래픽만 받는것과 같은 정책 정의가 가능하다.
- namespaceSelector
- 특정 namespace로 부터 들어오는 트래픽만을 받을 수 있다. 운영 로깅 서버의 경우에는 운영 환경 namespace에서만 들어오는 트래픽을 받거나, 특정 서비스 컴포넌트의 namespace에서의 트래픽만 들어오게 컨트롤이 가능하다. 내부적으로 새로운 서비스 컴포넌트를 오픈했을때, 베타 서비스를 위해서 특정 서비스나 팀에게만 서비스를 오픈하고자 할때 유용하게 사용할 수 있다.
- Protocol & Port
- 받을 수 있는 프로토콜과 허용되는 포트를 정의할 수 있다.
Egress 트래픽 컨트롤 정의
Egress 트래픽 컨트롤은 ipBlock과 Protocol & Port 두가지만을 지원한다.
- ipBlock
- 트래픽이 나갈 수 있는 IP 대역을 정의한다. 지정된 IP 대역으로만 outbound 호출을할 수 있다.
- Protocol & Port
- 트래픽을 내보낼 수 있는 프로토콜과, 포트를 정의한다.
예제
아래 네트워크 정책은 app:apiserver 라는 라벨을 가지고 있는 Pod들의 ingress 네트워크 정책을 정의하는 설정파일로, 5000번 포트만을 통해서 트래픽을 받을 수 있으며, role:monitoring이라는 라벨을 가지고 있는 Pod에서 들어오는 트래픽만 허용한다.
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: api-allow-5000
spec:
podSelector:
matchLabels:
app: apiserver
ingress:
- ports:
- port: 5000
from:
- podSelector:
matchLabels:
role: monitoring
이외에도 다양한 정책으로, 트래픽을 컨트롤할 수 있는데, 이에 대한 레시피는 https://github.com/ahmetb/kubernetes-network-policy-recipes 문서를 참고하면 좋다.
Secret
Secret은 Password, API key, SSH key 등 보안이 중요한 정보를 컨테이너에 주입해야할 때 사용되는 리소스 이다.
- ConfigMap과 사용법은 비슷하다. 다만 ConfigMap이 민감하지 않은 설정 정보를 컨테이너에 주입하는 게 목적이라면, Secret은 반대로 민감한 정보를 안전하게 컨테이너에 주입하는 게 목적이다.
- Kubentes는 기본적으로 Secret 값을 etcd에 저장하는데, Base64 인코딩을 한다. 즉, etcd에 접근권한이 있다면 Secret을 읽는 게 어려운 일이 아니다.
- 따라서 클라우드 서비스 같은 경우엔 암호화를 거칠 수 있도록 추가적인 방법을 제공한다. (가령 EKS를 사용하면 KMS로 encrypt 할 수 있다.)
- 그럼에도 가장 중요한 건 읽기 권한(사용자 접근 제어 관리)이다. RBAC(Role Based Access Control)을 활용해 Secret 오브젝트에 대한 읽기권한을 누가 가질 수 있게 할지에 대해 설정을 잘 해야 한다.
- 가령 ConfigMap과 Secret을 구분해서 보관하여 사용자별로 권한을 나눠서 주는 방식이 예시가 될 수 있다.
Secret 에 여러 type 이 있는데, https://kubernetes.io/ko/docs/concepts/configuration/secret/#secret-types 문서를 참고한다.
Ingress TLS
Ingress는 클러스터 내 여러 서비스에 대한 트래픽을 관리합니다. TLS를 Ingress 레벨에서 설정함으로써 각 서비스마다 개별적으로 설정할 필요 없이 중앙에서 관리할 수 있습니다.
다음은 TLS를 설정한 Ingress 예시입니다.
참고 : https://kubernetes.io/docs/concepts/services-networking/ingress/#tls
apiVersion: v1
kind: Secret
metadata:
name: testsecret-tls
namespace: default
data:
tls.crt: base64 encoded cert
tls.key: base64 encoded key
type: kubernetes.io/tls
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: tls-example-ingress
spec:
tls:
- hosts:
- https-example.foo.com
secretName: testsecret-tls
rules:
- host: https-example.foo.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: service1
port:
number: 80
Sealed Secrets
SealedSecret 오브젝트를 생성하면 쿠버네티스 컨트롤러가 복호화하여 Secret 오브젝트를 생성하는 방식이다.
- SealedSecret를 사용하게 되면 kubeseal CLI라고 하는 또다른 커맨드 툴을 사용해야 하는데, 이 툴이 컨트롤러와 통신하며 데이터를 암호화하게 되는 것이다.
- SealedSecret은 클러스터 상에서만 복호화된 Secret 오브젝트가 사용될 수 있게 관리해 준다.
- 즉, git과 같은 pulbic 공간에는 데이터가 암호된 상태로 올라가기 때문에 보안을 보장받을 수 있다.
SealedSecret 은 다음과 같은 두 가지 구성요소로 이루어져 있다.
- A cluster-side controller / operator
- A client-side utility:
kubeseal
kubeseal utility 는 비대칭키를 통해 secret 을 암호화하고 이는 클러스터에서만 복호화할 수 있다.
다음의 SealedSecret 리소스는 kubeseal CLI를 통해 암호화된 secret을 포함하고 있다.
apiVersion: bitnami.com/v1alpha1
kind: SealedSecret
metadata:
name: mysecret
namespace: mynamespace
spec:
encryptedData:
foo: AgBy3i4OJSWK+PiTySYZZA9rO43cGDEq.....
클러스터에서 복호화하여 다음의 Secret 리소스를 생성한다.
apiVersion: v1
kind: Secret
metadata:
name: mysecret
namespace: mynamespace
data:
foo: YmFy # <- base64 encoded "bar"
Default SSL Certificate
팀에서는 TLS 인증서 관리를 SealedSecret 을 사용해서 암호화하고, 이를 git에 저장해서 사용한다.
도메인이 다른 경우 프로젝트 별로 ingress 에 TLS secret 을 따로 지정하여 사용하기도 하지만, 공통된 도메인인 경우는 ingress nginx의 Default SSL Certificate 를 사용하여 인증서를 하나로 관리할 수도 있다.
- Ingress nginx controller는 모든 요청을 핸들링 하며, --default-ssl-certificate flag로 기본 certificate를 설정 할 수 있다.
- 예를 들어, foo-tls 라는 이름을 가진 TLS secret이 default namespace에 있다면 --default-ssl-certificate=default/foo-tls 로 설정하면 된다.
- 각 서비스의 ingress에 tls가 설정이 되어 있고, secretName이 없다면 HTTPS redirect를 강제로 진행한다.
- ingress nginx도 일반적인 리소스와 같이 TLS secret 을 업데이트 하려면 reload가 필요하다. ( 참고 )